MobileUse: A GUI Agent with Hierarchical Reflection for Autonomous Mobile Operation
研究问题:为什么智能体执行总是失败?
移动 GUI agent 在真实手机任务里面临三类核心困难:
- 任务链条长,长程执行容易一路积累偏差。
- 单步动作错了以后,错误恢复很难。
- 一旦遇到陌生 app 或陌生页面,agent 会出现明显的 cold-start 问题。
现有方法虽然会加入反思模块,但很多反思只停留在单步动作层,既不一定真能纠错,还会带来额外延迟,甚至因为 hallucinated feedback 把操作带偏。
本文要解决的,正是移动长程任务中的“如何稳”和“如何在陌生环境里尽快熟”。
整体思路:自我反思的多智能体框架 | MobileUse
在上述问题中,我们意识到当前的预训练模型无法涵盖所有的知识场景,导致通用 agent 不可避免会出错,于是我们设计了一套自我反思的多智能体框架 — MobileUse (NeurIPS’25)。该框架通过主动探索采样收集的知识库构建我们对当前环境的认知,以及层次化的反思模块对错误步骤及时进行修正。
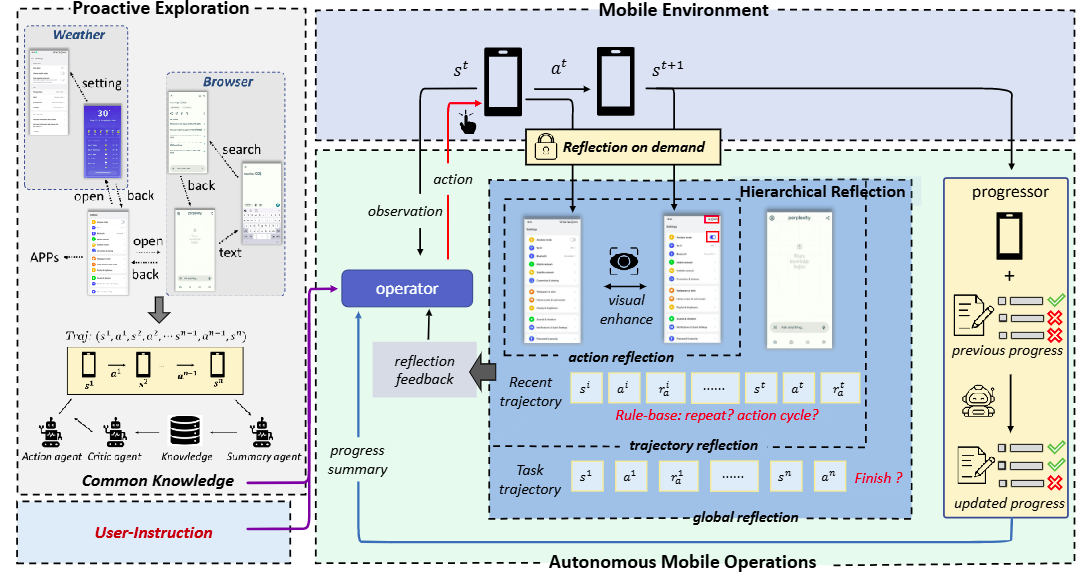
MobileUse 将系统设计成一个多智能体框架,核心组件包括:
Operator:负责实际执行动作Progressor:负责总结当前进度Hierarchical Reflectors:负责多层次反思Proactive Explorer:负责提前探索陌生环境并积累共通知识
MobileUse 的关键不是“让一个 agent 更聪明”,而是同时解决执行、总结、反思与知识积累四件事。
方法结构
1. Hierarchical Reflection:三层反思机制
在 GUI 执行场景中,许多任务往往需要经历几十步连续操作,例如跨 App 设置、填写表单或多层菜单导航,一旦某一步出现偏差,错误极易在后续步骤中不断放大。传统的端到端模型通常只能“向前执行”,缺乏对执行结果的自我验证能力。
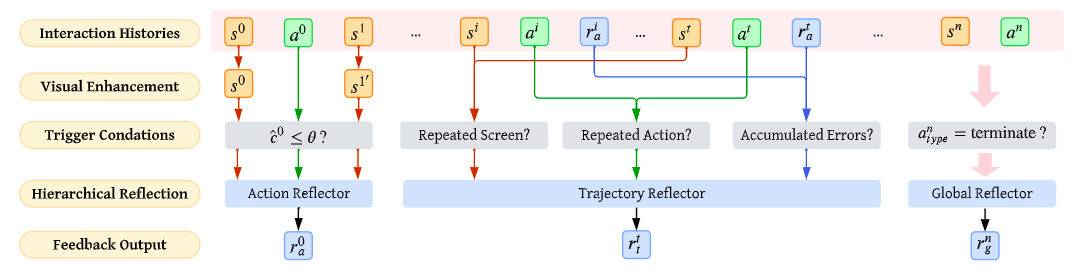
长程移动任务的失败并不都发生在同一个时间尺度上,因此反思也不能只有一种粒度。MobileUse 针对这一问题,引入了分层反思(Hierarchical Reflection)架构,让智能体在执行过程中具备持续自检与纠错的能力,人类在完成一项复杂任务时,会不断地进行自我检查和修正。
1.1 Action Reflector
Action Reflector 负责检查当前单步动作是否可靠,主要解决:
- grounding 错误
- 局部视觉误判
- 当前界面理解错误
但绝大多数步骤本来就是对的。如果每步都调用反思器,既慢,又可能因为错误反思而制造新错误。
MobileUse 加入了 Reflection-on-Demand:只有当动作 token 的平均对数概率低于阈值时,才触发 action-level 反思,在保证执行鲁棒性的同时,有效平衡了效率与性能。
1.2 Trajectory Reflector
有些错误并不是单步错,而是“每一步都看起来合理,但整体已经偏航”。为此,MobileUse 引入 Trajectory Reflector,它看的是最近若干步动作、短历史和已有 action-level 反馈,用来判断轨迹是否仍在朝任务目标推进。
它主要处理以下模式:
- 重复动作
- 重复截图
- 累积性的 action-level error
这一层负责发现“局部动作合理但整体任务进度不推进”的问题,避免动作陷入循环或者不合理的步骤中。
1.3 Global Reflector
Global Reflector 在任务将要结束时介入。因为在长程任务中,agent 很可能过早宣布完成,或漏掉某些关键子目标。
Global Reflector 会综合历史动作和最新截图,判断:
- 任务是否真的完成
- 是否只是提前 terminate
- 是否需要返回继续执行
这一层的作用,是把“是否结束”从 operator 的主观判断里抽出来,做一次全局校验。
2. Proactive Exploration:先熟悉环境,再执行任务
除了反思,MobileUse 的第二个核心设计是 Proactive Exploration。许多失败并不是因为 agent 不会推理,而是因为它对陌生 app 根本没有基本操作知识。
知识库能为 agent 执行过程提供充足的可参考信息用于决策,因此受到广泛关注。常见的知识库构建方案有两种:
-
人工收集有效的知识,经过结构化的梳理为知识库,在使用时根据知识的相似性进行召回;
-
人工构建任务让 agent 自动化执行,通过持续的试错尝试完成这条任务对应的知识。
这些方案不仅依赖人工构建的任务与知识分布,可能导致存在冗余与 bias,与真实任务偏差较大,而且检索召回难度大,仅通过任务或知识进行匹配都难以真正有效召回。
因此,我们在设计上抛弃了传统的任务构建环节,采用多智能体自我驱动的主动探索方案,让智能体在环境内自由探索,适用于在未知环境的冷启动。
具体来说分为三个阶段:
-
action agent 基于主动探索的 prompt,指导其不断自我驱动探索当前界面有价值的按钮,从而驱动整个 UI 状态的变换;
-
随着 action agent 不断生成动作,逐步形成一条 轨迹 = <界面,动作,下一个界面…..>, summary 识别整条轨迹中有价值的操作轨迹并将其汇总为可重用的经验总结,从而建立数据探索和知识生成的自动化 pipeline。
-
critic agent通过参考积累的总结经验来指导 action agent的下一步执行,避免重复的探索,更有效率地进行下一步探索。
主要结果
1. 在 AndroidWorld 和 AndroidLab 上达到 SOTA
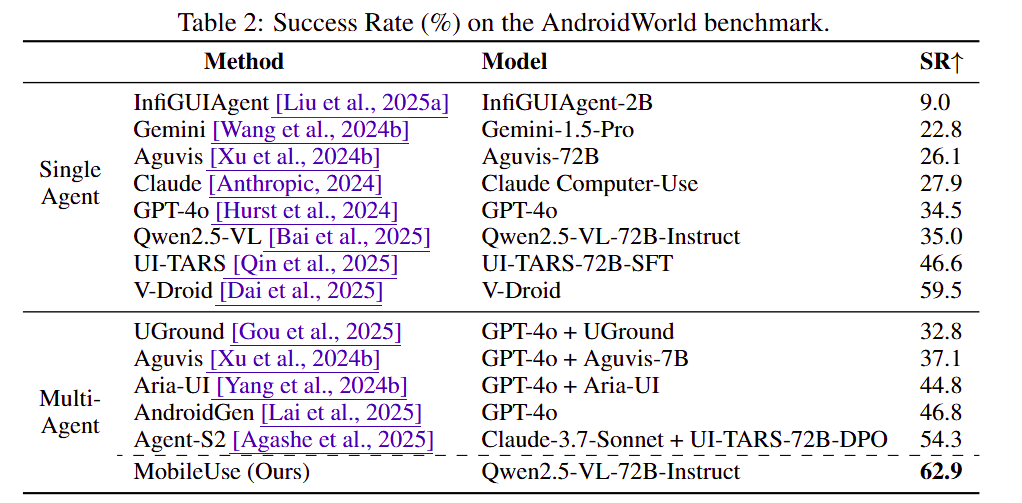
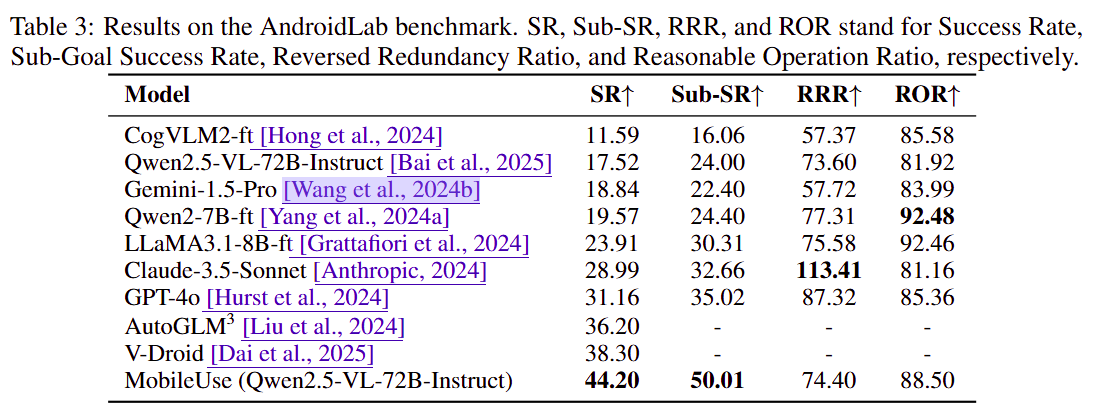
结果显式,MobileUse 在两个动态 Android benchmark 上都达到当时 SOTA:
AndroidWorld:62.9%AndroidLab:44.2%
在 AndroidWorld 上,相较基于 xml 解法 V-Droid 进一步提高了 3.4%;相较强基线 Agent-S2 提升 8.6%;相较单体 Qwen2.5-VL-72B-Instruct,成功率提升 27.9%。实验结果表明,分层反思与主动探索机制在中高难度任务中尤为有效,能够显著减少感知、导航和交互相关的失败。
2. 层级反思本身就能带来明显增益
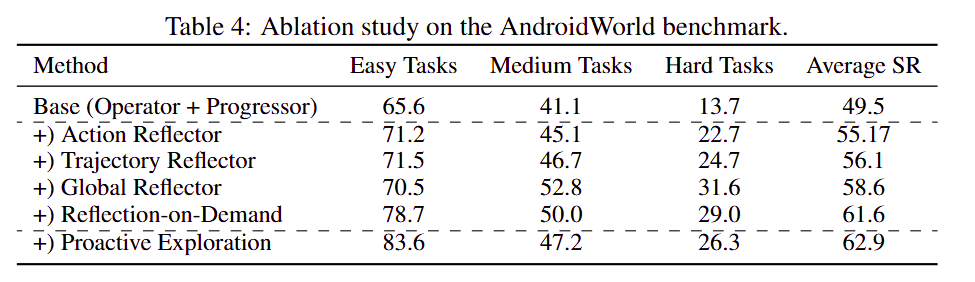
在消融实验里,MobileUse 架构设计中:
- 三层 reflectors 都有效;
- 尤其对 medium 和 hard 任务更重要;
- 加入完整层级反思后,整体
SR提升约12.1%。
这说明长程任务的鲁棒性问题,确实不能只靠单步动作纠错来解决。
3. Reflection-on-Demand 比“每步都反思”更合理
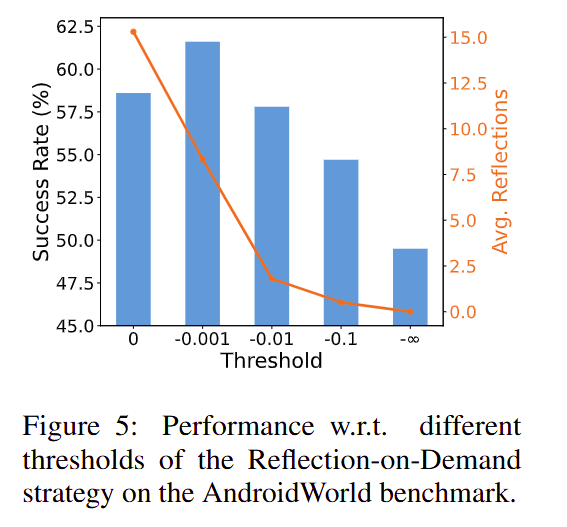
论文发现,当基于动作置信度只在必要时触发 Action Reflector 后:
- 可以减少大量无效甚至错误的反思;
- 在省掉大部分反思调用的情况下,成功率下降很小;
- 说明真正关键的只是少数高风险步骤。
进一步分析可以发现,当阈值设置合适时,即使省去超过 85% 的反思,成功率下降也不到 1.5%。这强化了一个重要判断:反思的价值在于“关键时刻介入”,而不是“处处介入”。
4. 主动探索对陌生环境确实有帮助
在层级反思的基础上,再加入 Proactive Exploration 后,整体 SR 继续提升 1.3%,在 easy task 上提升 4.9%。
这个结果说明,很多所谓“执行错误”,其实在更早阶段就已埋下:agent 根本不知道陌生 app 的基本布局和任务习惯。主动探索提供的正是这种先验知识。
总结与展望
在当前智能体研究与应用快速发展的背景下,真正限制 Agent 能力上限的并非单一模型的理解或推理能力,而是其在真实环境中持续执行、纠错与适应的能力。
尤其是在移动端 GUI 这样的高动态、强交互环境中,Agent 不仅需要“知道该做什么”,更需要“知道自己是否做对了”,以及在不确定环境中“主动建立对世界的理解”。
MobileUse 重新审视了 Agent 与环境之间的关系,将环境视为一个需要持续感知、验证与学习的对象,而非一次性输入。为此,系统在执行层面引入了多层次的反思机制,使 Agent 具备了“执行即验证”的能力。
主动探索赋予 agent “好奇心”与“动态进化”的能力,反思给 agent 带来了“自我思考与纠错”的灵魂,探索让 Agent 建立对环境的初始认知,反思则在执行过程中不断修正和强化这一认知,整体构成了 Agent 的自我进化闭环。
未来随着大模型规模与训练语料的扩展,其内化的知识会更充分,知识库外挂的策略显得比较笨重,但反思能力的内化会随着模型的增长显得更为重要,如何更好地构建具备自我反思的 agent 才是凸显其智能的关键。